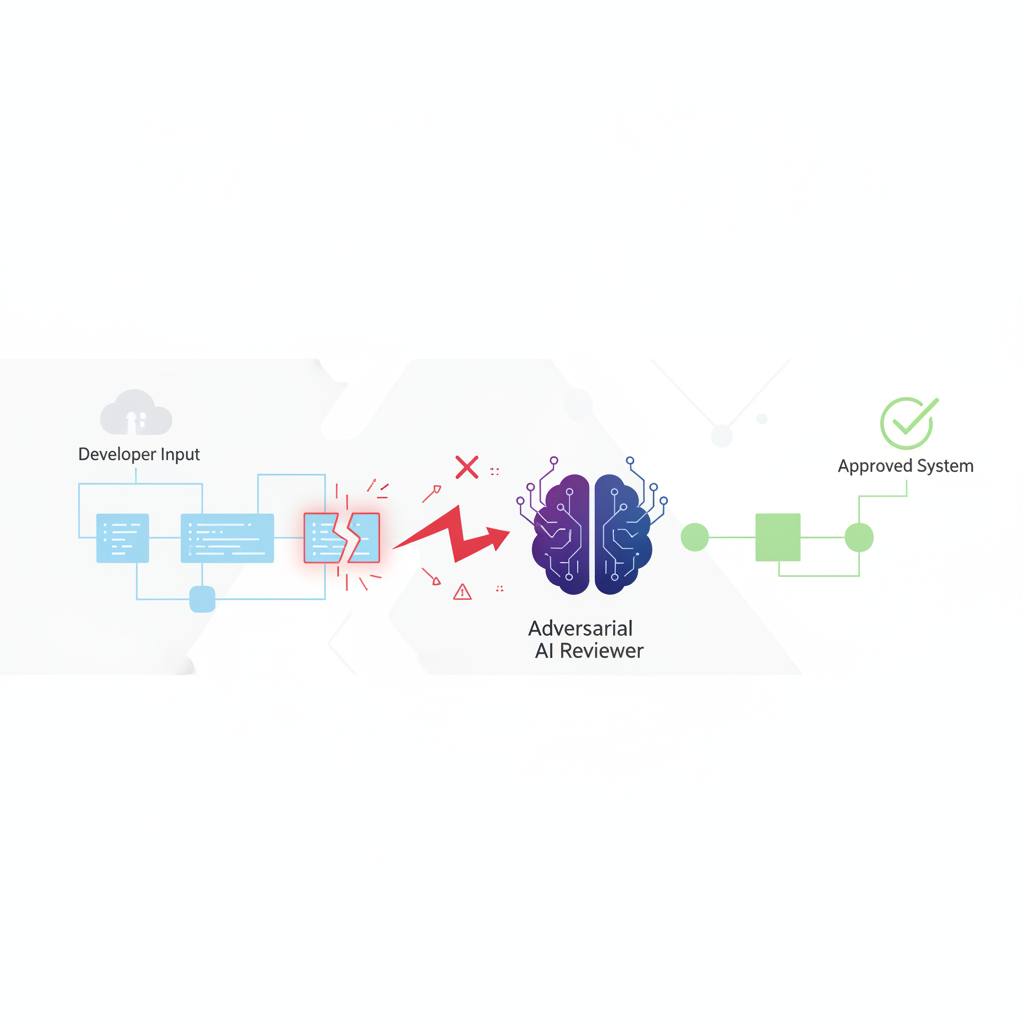
كشف مطور عن نظام جديد مفتوح المصدر يُسمى «agent-plan-review-loop»، يهدف إلى جعل مراجعة خطط الكود بواسطة الذكاء الاصطناعي أكثر دقة وصرامة. على عكس نماذج اللغة الكبيرة المتفائلة عادةً، تقوم هذه الأداة بتحدي الخطط بشكل متعمد لاكتشاف الأخطاء غير الواضحة.
إذا كنت تعمل في مجال تطوير البرمجيات، فربما تكون قد لاحظت أن نماذج الذكاء الاصطناعي الكبيرة (LLMs) يمكن أن تكون متفائلة جدًا عند مراجعة خطط الكود. هذا يعني أنها غالبًا ما توافق على خطط قد تحتوي على أخطاء واضحة مثل مسارات ملفات غير موجودة، أو توقيعات دالة غير صحيحة، أو حتى افتراضات خاطئة عن الكود الفعلي. المشكلة هي أن هذه النماذج تعتمد على بيانات تدريبها وسياق المحادثة بدلاً من فهم حقيقي لمستودع الكود الخاص بك. لكن هناك خبر جيد: لقد قام أحد المطورين بإنشاء نظام جديد مفتوح المصدر يُسمى «agent-plan-review-loop» ليحل هذه المشكلة. هذا النظام يقدم مراجِعًا للخطط البرمجية يعمل بأسلوب 'خصومي' (adversarial)، مهمته الأساسية هي إثبات أن خطتك خاطئة. تخيل أن لديك زميلًا خبيرًا يصر على البحث عن العيوب في كل خطة، هذا ما تفعله هذه الأداة. كيف يعمل هذا؟ بدلاً من أن يكون المراجِع والكاتب على دراية بنفس سلسلة التفكير، فإن «agent-plan-review-loop» يفصل بينهما تمامًا. يتم تخزين كل جزء من العملية (الخطة، المراجعة، الأسئلة، القرارات، الفروقات) كملفات نصية في المستودع. يقوم المراجع بتشغيل عملية منفصلة تمامًا، ويحصل فقط على خطة التنفيذ ومستودع الكود الفعلي والتعليمات المحددة له. لا يرى المراجع أبدًا الأسباب التي دفعت الكاتب لإنشاء الخطة. يتم إعطاء المراجِع تعليمات واضحة وصارمة: «أنت مراجِع خبير متشكك. ابحث عن أسباب فشل هذه الخطة. لا تُثنِ عليها. افتراضك الافتراضي هو طلب التغييرات؛ لا توافق إلا إذا كانت الخطة سليمة تمامًا.» هذا النهج يجبر المراجع على تقييم الخطة بناءً على مزاياها الخاصة مقابل الكود الحقيقي، مما يكشف عن عدد مدهش من الأخطاء التي كانت ستمر مرور الكرام. هذه الأداة لا تغير فقط كيفية مراجعة خطط الكود، بل تجعل العملية أكثر قوة وموثوقية، مما يوفر وقتك ويقلل من الأخطاء المستقبلية. هذا يعني كودًا أفضل وأقل مشاكل في المستقبل بالنسبة لك وفريقك.